
Reading notes for Architecture Patterns with Python by Harry Percival, Bob Gregory
Notes, references and codes I wrote while reading and coding along Architecture Patterns with Python by Harry Percival, Bob Gregory - O’Reilly.
Work in progress
My code along repository bmaingret/architecture-patterns-code-along.
The full code by the authors is also available, as well as their book at github.com/cosmicpython.
- Chapter 1 - Domain model
- Chapter 2 - Repository Pattern
- Interlude - Reproducibility and Continuous Integration
- Chapter 3 - Coupling and Abstractions
- Chapter 4 - Service Layer pattern
- Chapter 5 - TDD in High Gear and Low Gear
- Chapter 6 - Unit Of Work
- Chapter 7 - Aggregate and Consistency Boundaries
- Chapter 8 - Events and the Message Bus
Chapter 1 - Domain model
The domain is a fancy way of saying the problem you’re trying to solve
The domain model is the mental map that business owners have of their businesses
Diving in the domain model
- Understand the business jargon and keeps a glossary
- Get concrete examples of the rules defining the domain model
- TDD: translates those rules into unit tests
Value Object Pattern
any domain object that is uniquely identified by the data it holds; we usually make them immutable
Which in Python can easily be converted to frozen dataclasses, offering hash for free.
@dataclass(frozen=True)
class OrderLine:
order_reference: str
sku: str
quantity: int
Note however than because SQLAlchemy modifies the class at runtime, we have to use unsafe_hash=True instead…
Domain entity
Domain object that has long-lived identity
Usually mutable and have a fixed identity not depending on their values.
We usually make this explicit in code by implementing equality operators on entities:
In Python that means defining the __eq__ operator.
Careful when defining hash, which basically means identifying what uniquely defines an entity along its life.
Not everything must be in a class
Domain Service Function: in Python we can put the function in the module without making it more than that.
Exceptions as domain concepts
Business errors/exceptions can be nicely represented by exceptions
class OutOfStock(Exception):
pass
Chapter 2 - Repository Pattern
Repository pattern
Make an abstraction around the storage. Looks like everything is stored in-memory and allows for
Port and Adapter
Port usually is some interface, and adapter its implementation. In Python, this usually translates to some abstract base class and its implementation, but it can also be an implicit duck type port.
ORM
ORM can lead to high dependency towards the ORM framework, and one must be careful to invert the dependency and makes the ORM depends on the domain models instead.
Interlude - Reproducibility and Continuous Integration
Although I had read a lot and knew this was the way to go, I never took the time to implement it in any of my project, so I thought this would be a good opportunity, even more since the original authors take this path as well (Makefile and Docker).
Development and Production Environment - Python mess
I mostly followed https://ealizadeh.com/blog/guide-to-python-env-pkg-dependency-using-conda-poetry
I had so much trouble making everything work under plain Windows, that I moved all my Python dev to WSL2.

https://xkcd.com/1987
I had learned of Poetry a year ago, but still stuck to Conda. I never liked the Conda way of handling dependencies, but it is still of great help to install some data science tools that are not pure Python.
- Install Conda (I prefer to use the Miniconda installer)
- Install Poetry (through the install-poetry.py script). N.B. this requires a working installation of Python, so if you only installed it with Conda, install it through a shell with a Conda environment active.
- Create a minimal Conda environment (
conda create --name remote-work-env python=3.8.5orconda create --file environment.yml) - Set up a new project/Init an existing project using Poetry (e.g.
poetry initfrom within an existing directory). N.B. Poetry should pick up the active Conda environment and not create a new one. - Manage dependencies with Poetry (
poetry add sqlalchemy,poetry add --dev pytest)
Github Actions
Github Actions are a recent (and welcome) addition to Github, allowing CI/CD workflow right in Github. Although it is possible to stay in the Github ecosystem, some Actions still depends on external tools and API.
To get a good starting example, one can go to the Actions tab in a github repository, and at the Choose a workflow template select Skip this and set up a workflow yourself, an editable configuration template will be made available right from the browser.
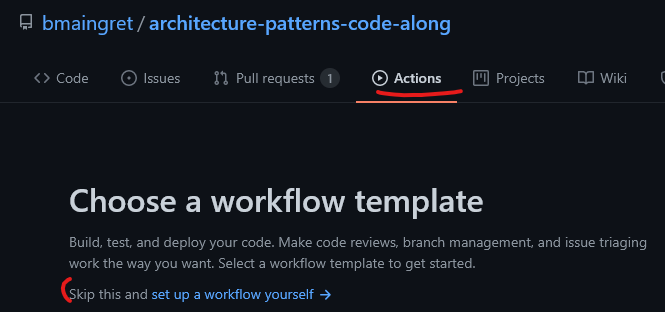
For this repository, I have a single workflow containing the test passing, test coverage, linting and formatting. The Python setup is done thanks to an available Github Actions, dependency install thanks to Poetry, coverage through pytest-cov and codecov, and finally linting/formatting thanks to pre-commit.ci. More on that in next part on pre-commits.
Git hooks - Pre-commit
Instead (or in addition) of automating code quality checks before merging, we can take part of the git hook to check these before even committing. Thanks to some good people, we have an awesome Python tool for that: pre-commit.com. Once installed, configuration can be made through a .pre-commit-config.yml file and then installed with pre-commit install. Once installed you can see the generated Python script file .git/hooks/pre-commit.
To configure hooks with pre-commit, you need to specify git repositories. Several hooks are available at the pre-commit repository, among which I configured:
- check-yaml
- check-toml
- end-of-file-fixer
- trailing-whitespace
To this I added Flake8 a Python linter, and black a code formatter (this will modify your code, although you can make it not, but that would go against the point).
Note that thanks to pre-commit.ci, the same configuration file can be used both to install the hooks locally, and to run checks in a Github Action.
Chapter 3 - Coupling and Abstractions
reduce the degree of coupling within a system by abstracting away the details
Some key takeaways:
- Abstractions and decoupling help for testing (c.f. the repository pattern).
- Separate the core logic code from external states.
This usually allows to do edge-to-edge testing, faking some details (quite often I/O). This requires some additional abstractions (around the filesystem for instance) and new explicit dependencies on this abstractions).
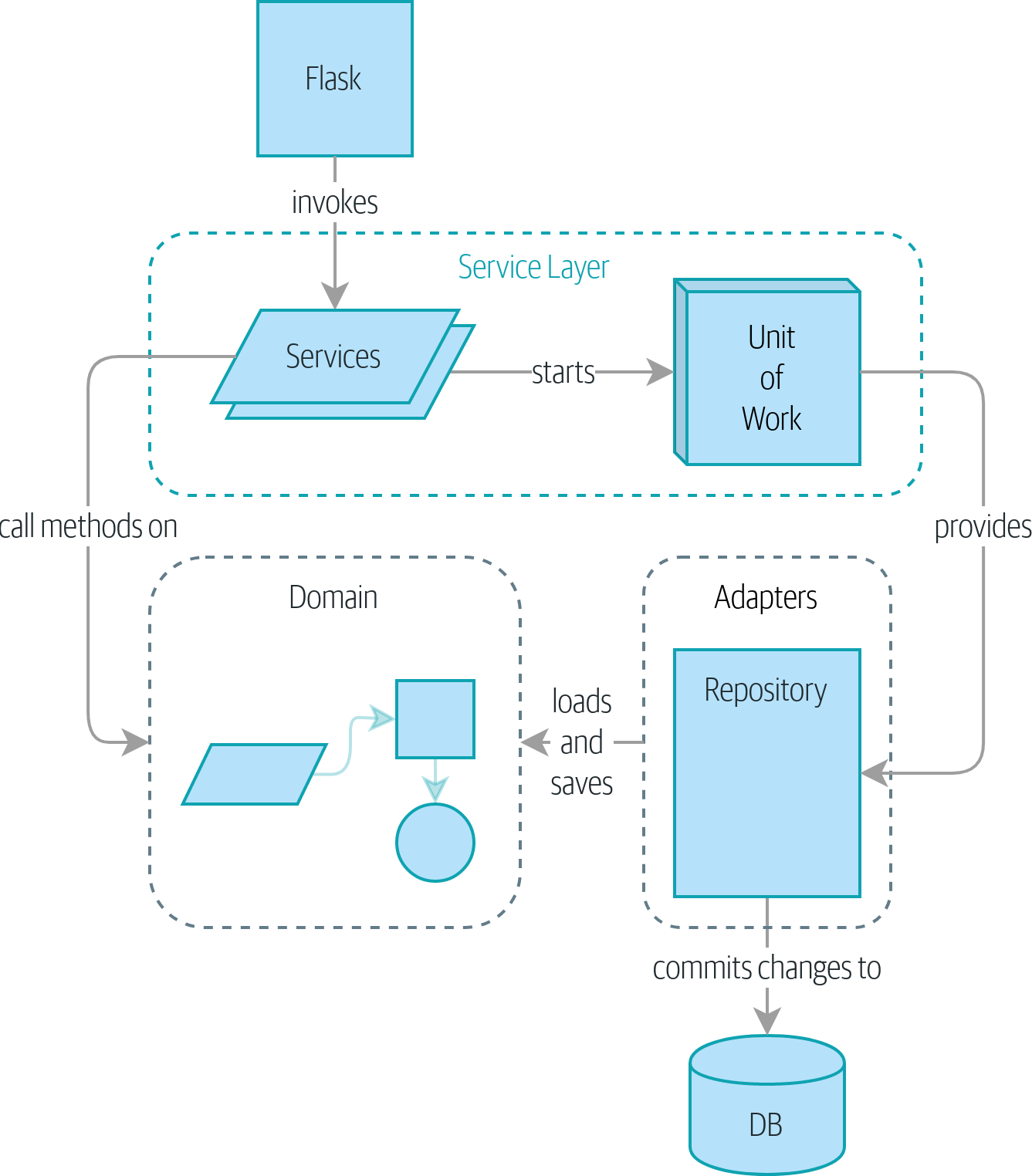
Chapter 4 - Service Layer pattern
Also called an orchestration layer or a use-case layer.
- Service layer exposes the domain service functionalities through endpoints to the external world.
- It wraps the boring stuff such as validate entry, calling the domain model and updating it, and finally persisting anything
- Interacting with our domain model is easier and allows for different type of interactions (cli, web, etc.)
- Ease the high level and end-to-end tests, allowing for fewer tests, and easy refactoring of underlying domain models
Although the concept of service is interesting, this chapter leaves things in a dubious state with still a lot of coupling towards the ORM from both the Flask app and services, the low details of domain implementations are everywhere, and testing is getting more and more difficult to init properly.
Chapter 5 - TDD in High Gear and Low Gear
Analogy made with biking where yous tart with low gear (unit tests) and then start moving towards higher gears (e2e tests). Allowing to hide further more the implementation details and to have tests with less coupling towards implementation details.
To reduce coupling with domain models:
- Fixture functions to help initialize domain models
- Adding services that will handle the domain models
I’ll just copy/paste from the book here for rules of thumb regarding tests to implement:
Aim for one end-to-end test per feature
Write the bulk of your tests against the service layer (edge-to-edge)
Maintain a small core of tests written against your domain model (maintain is the important word here: start with a lot and delete once they are covered by services)
Error handling counts as a feature
Express your service layer in terms of primitives rather than domain objects.
Chapter 6 - Unit Of Work
Services and API are still tightly coupled with the data persistency and session management. Unit of Work define a single entry point for data storage, allowing to nicely handle transactions (commits, rollbacks, failures, etc). It also eases the integration between the service and the repository layers.
In Python, it fits very well the context manager type.
Chapter 7 - Aggregate and Consistency Boundaries
Invariants are conditions that are always true.
Constraints are rules that restricts the possible states of the model
In order to ensure invariants and constraints, and in addition of the logic behind, we need to ensure the data integrity, especially in concurrent operations. While we could lock the entire table/database we are manipulating this won’t scale up. The aggregate pattern groups up several domain objects in a container and allow to manipulate them as a single entity, thus ensuring data integrity and consistency of everything in it (the actual implementation will ensure it, not the simple use of the aggregate pattern).
The choice of aggregates is not simple and depends of the constraints of each project. Keep in mind that the less data in the domain models, the easiest it is to ensure invariants and constraints.
{kind=link}
Handling concurrency
Optimistic concurrency: suppose things work fine most of the time
- Locking things at db level usually comes with performance cost -> usually used in a pessimistic concurrency mindset
- Using version numbers to control update and be able to detect and recover from concurrent updates
Note: there is a lot a db specific way of implementing locking at different levels (consistent read, select for update, etc.)
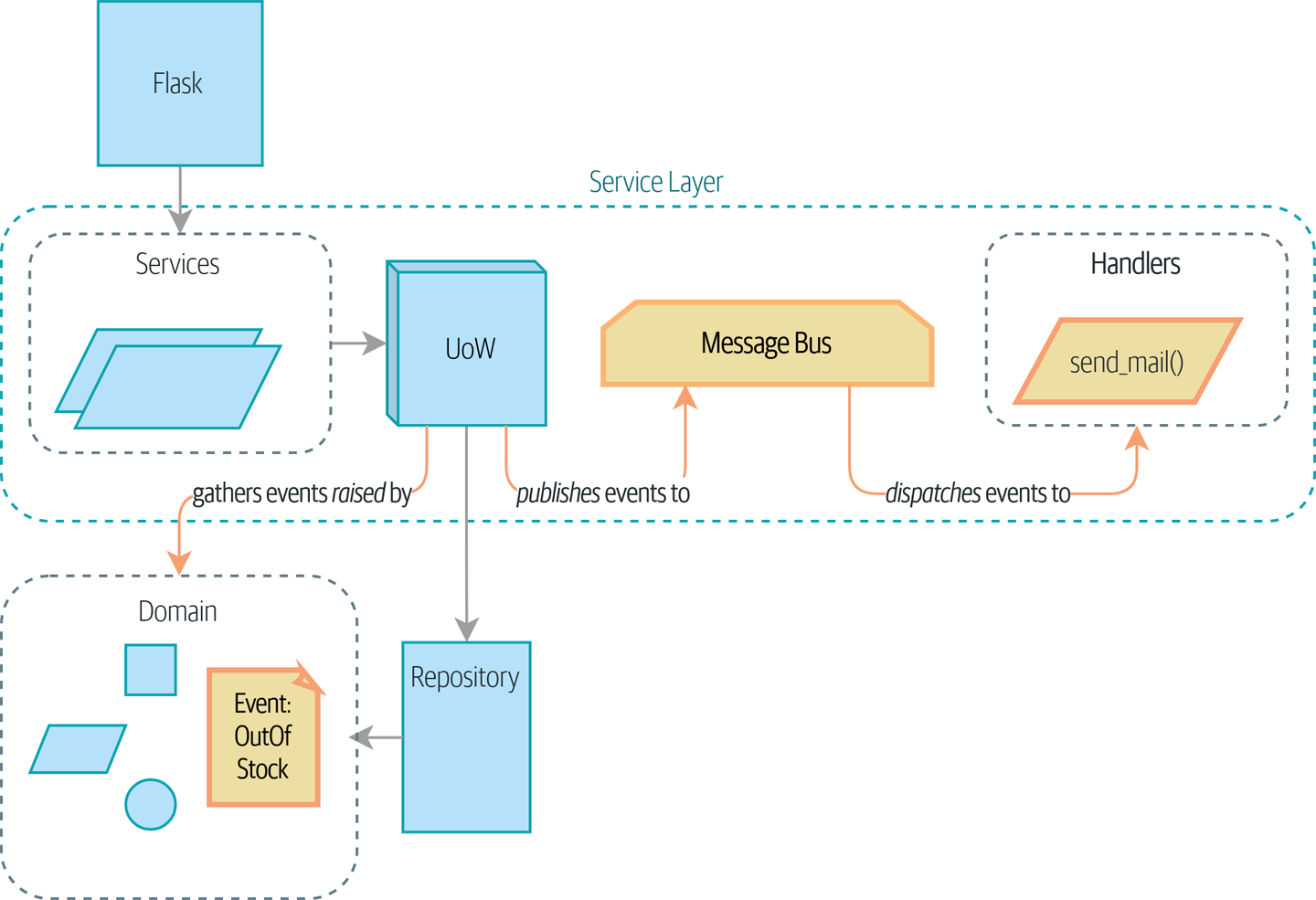
Chapter 8 - Events and the Message Bus
Events help to enforce the Single Responsibility Principle (the S of SOLID), preventing having multiple use cases tangled in a single place.
Message bus allows to route the event messages to the different handlers. Typical middleware.
Events can be raised and handled at different places:
- Service layer takes events raised by the models and send them straight to message bus
- Service layer raises events directly to the message bus
- UoW collects events from aggregates and send them to the message bus
{kind=link}
Chapter 9 - Going to Town on the Message Bus
Using the message bus as an entry point for the service layer.
- allows to be granular and stick to SRP
- allows to write tests in terms of events.
Service functions become event handlers, and as such all internal and external actions are managed the same way, through event handlers.
When large changes are incoming adopt
follow the Preparatory Refactoring workflow, aka “Make the change easy; then make the easy change”