
Reading session #2
Articles
- Bringing Machine Learning models into production without effort at Dailymotion
- How To Run a Python Script Using a Docker Container
- How to build a DAG Factory on Airflow
- Deploying Machine Learning into Production: Don’t do Labs.
- MLOps Is Changing How Machine Learning Models Are Developed
Bringing Machine Learning models into production without effort at Dailymotion
Source: medium.com/dailymotion
How we manage to schedule Machine Learning pipelines seamlessly with Airflow and Kubernetes using KubernetesPodOperator
Life cycle of a machine learning model - Dailymotion (c)
They followed what I would call a classic evolution:
- First a containerized approach with an always up VM-like and simple cron-like schedule
- Then VM-like instantiation to run the container on-demand
- Finally define node pools of different types allowing to run on-demand container and share resources
All of this thanks to the good integration between Airflow and Kubernetes (c.f. KubernetsPodOperator).
In the article they mention Kubeflow a Google service specifically thought for Machine Learning Workflow.
How To Run a Python Script Using a Docker Container
Source: towardsdatascience.com
Very simple introduction to setting up a Docker with required tools and software. Although I find Docker very attractive for reusability it does require do put everything explicitly which in my typical working environment based on conda can be a pain if I don’t want to add too much useless overhead.
How to build a DAG Factory on Airflow
Source: towardsdatascience.com
I encountered similar concern when trying out Jenkins at work, and there was very little example on how to set things up properly. In addition, since I am more of a configuration over code type of guy, I wanted to take part of recently introduced Jenkins Pipeline. Trying to set up the two while being the only knowledgeable person on this topic seems like too much work and an unnecessary SPOF for our needs in the end.
In this case the final result is appealing but it still seems a bit of a hack (assumptions of only Python files, and relying on hardcoded heuristic DAG detection rule) and I’d rather like that a tool such as Airflow provides some common interface for this.
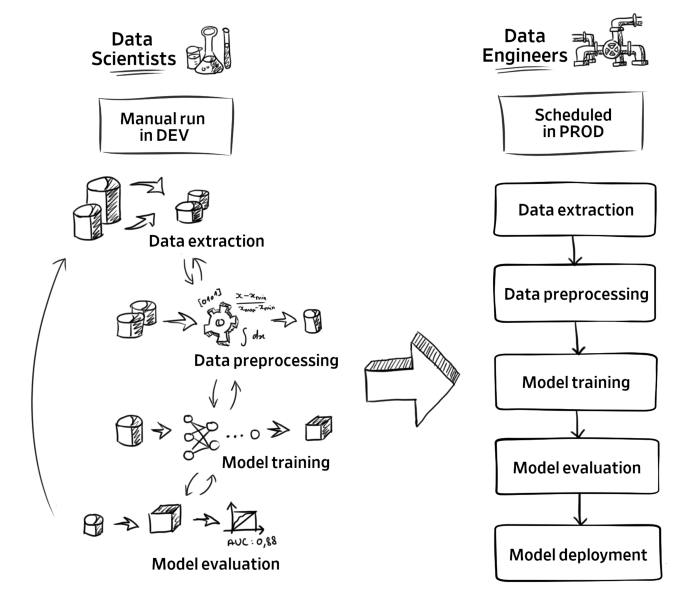
Deploying Machine Learning into Production: Don’t do Labs.
Source: towardsdatascience.com
Although I was aware that a large majority of data science projects don’t make it to production (87% claimed here), this article states that this is not due to the lack of value for the models but more to the difficulty to scale.
- Gap between data scientists and data engineers
- Development in isolated environments away from user interaction, production constraints and businesses
- ML adds additional metrics to monitor that can be either difficult to implement or to foresee (e.g. gender bias)
I thought this article would describe how to industrialize development environment to match the production environment but it actually makes a point that this is not enough. They put data scientists in the existing product teams where they work as additional resources. This allow first to work hands-on with the people that are responsible for the end product, and also for the product owner to make enlightened decisions on where to put effort.
Some advantages of working in labs that are yet to be replicated in their new paradigm:
System Thinking
- Allow to get out of the team routine and approach each problem from with a fresh perspective
Ideal Design
- Don’t limit yourself to what seems possible and not what would be ideal
Always be Innovating
- Use cutting-edge tools and solutions without having limitations on what will be possible. Explore and test without having to think rentability and production efficiency.
MLOps Is Changing How Machine Learning Models Are Developed
Source: kdnuggets.com
MLOps has to be one of the most popular topic in ML world today. Here a few key points are addressed to show the implication of moving from ML labs to proper production-ready ML.
Version Control is Not Just for Code
Data versioning is a big concern in ML. With continuously larger data sets typical versioning tools might not be applicable. In addition, GDPR-like concerns means that data is usually more sensitive information than code-base.
Build Safeguards into the Code
Checking the input data used for training, validation, etc. prevent big swings in your models trainings. Similarly checking differences between the previous and new models allows early detection of issues (could be done by checking element by element prediction differences).
The Pipeline is the Product – Not the Model
You give a poor man a fish and you feed him for a day. You teach him to fish and you give him an occupation that will feed him for a lifetime.”
Only the whole pipeline allows for proper control over the models and in the end, positive value for the project.
I’d cross this with previous article on data scientists working in labs. Even a well designed and defined pipeline might not be production ready nor usable in real-world.